


While most companies aim to monopolise their users’ attention, we at CityFALCON try to reduce the attention burden so users can more efficiently and effectively participate in the markets. Similar Stories Grouping takes us a step in that direction, so users can spend less time on due diligence and more time making decisions, being with friends and family, and doing their hobbies.
Anytime a major event occurs, both traditional and social media light up with reports, tweets, and posts about the happenings. In international cases, these are usually published in multiple languages, too. Most of the reporting, especially when the news is breaking, may be stub articles saying very similar, basic facts. As time progresses, more information comes out and the amount of information expands, causing news sources to diverge slightly in their takes. However, the underlying message across news platforms tends to remain very similar – assuming no fake news is presented.
This conformity can waste precious research and due diligence time because the stories repeat the same information. With Similar Stories Grouping, CityFALCON eliminates the need to scour multiple similar interpretations of the same issue.
On the other hand, some market participants fear missing out on subtle or obscured key differences that might lead to a better investment decision. Such participants seek all available similar content to get a better understanding of the issue (including that in other languages), and this approach is highly recommended for anyone about to make a financial or business decision.
Similar Stories Grouping helps these users by grouping all that content together in a single place, so multiple instances of similar information can be found all at once in a single location. This prevents the overlooking of important differences by haphazardly searching through the news feed for similar content. Additionally, when multiple languages are involved, CityFALCON captures and clusters multilingual content together.
Appearance and Benefits of Similar Stories Grouping
Similar stories appear on all CityFALCON deliver channels: the mobile apps, the website, and the API. In previous iterations of our platform, all stories occupied their own story cards, each story or Tweet its own line with all the associated information. With very popular topics or when major breaking news events occurred, the feed might flood with news article after news article (and definitely Tweet after Tweet) reporting the same thing.
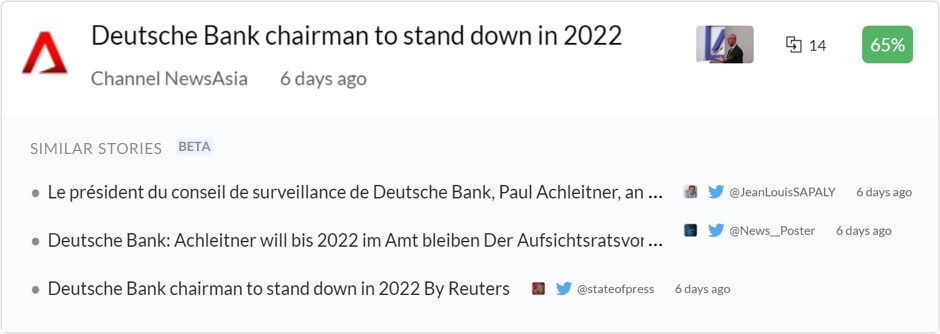
Similar Stories condenses all of those individual cards containing similar content into a single card with a representative headline. The similar content is printed in the same card for quick access to skimming but without taking up so much space.
Content curation – recording whether you like, dislike, or find stories irrelevant – can now be performed for all similar content in a single action, too. Curation helps our machines better understand your needs to increase the relevancy of content served to you. With this single-click action for multiple stories, you can help the algorithms learn faster. If you want to curate stories individually, you will need to ungroup similar content.
In this context, the “hide” curation tool lets you hide all the similar content so you can move on to the next idea without constantly encountering information you have already internalised.

Similar Stories Card with curation tools highlighted
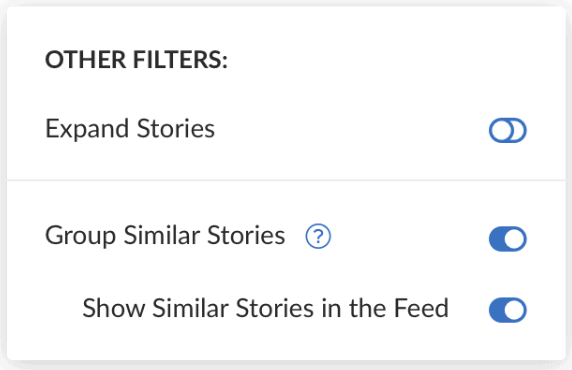
The default news feed on CityFALCON now condenses similar content into cards like this. If you want to go back to the old view, simply turn off the toggle switch for Group Similar Content. This will force each story to be presented on its own individual card in the feed.
To see only the most representative story – that is, hide all the similar content collected at the bottom of the grouped card – you can turn off Show Similar Content in Feed. This is useful for scanning the news without getting sidetracked by reading too many similar headlines that might grab your attention. Be aware that this does hide any content that is tagged as “similar”, except for the most representative piece of content, which will headline the card.
In short, if you want to skim the news and read about many different topics, turn off Show Similar Content in the Feed. If you want to dive deeper or just want to keep other headlines around for their slightly different interpretations of events, keep both options for similar content turned on.
How We Do It
To group stories together, our algorithms analyse each story title, meta description, and, if available as a full-text article on our platform, the story itself. We also analyse Tweets. Then, with all of this information, we vectorise the content and place stories and Tweets into clusters. Next, using the same analysis data but a different natural language processing (NLP) algorithm, we choose the most representative story for that group. If there are still too many stories, the process of clustering and choosing a representative is repeated.
Finally, the most representative stories are served to users as the headline story of the card and those in the cluster are presented as similar stories. Adding significant value over some incumbents like Google News, our machine-learning NLP models allow us to cluster and compare regardless of the language of the content. So, if there are multiple languages discussing the same topic, CityFALCON will group these together, as long as we support the language for grouping. As of June 2020, this support covers 16 languages, with up to 93 by the end of the year.
Clustering and Loss of Information
Using technology to condense linguistic information into a smaller set raises some common questions. How accurate is it? How do I know the clusterings are really “similar”? Does this approach condense the information too far so I will miss important information?
Let’s start with accuracy. At least for the languages you speak, it is easy to confirm that the content marked as similar is truly similar. You can still read the headlines, and you can instantly verify whether it is similar or not. While machine learning means accuracy will not be 100%, we only released this feature after testing, training, and refinement led to practical accuracy. Even humans are unable to be 100% accurate – and humans cannot read 1 million stories and Tweets a day to find similarities like our algorithms can. So while accuracy may not be 100%, it is sufficiently high for practical use. If you notice extreme inaccuracies, please let us know so we can improve our systems.
In the same way as for accuracy, it is easy to verify that the clusterings really are similar, since the headlines are presented for inspection.
Finally, as long as the other stories are displayed in the news feed under the Similar Content header, users will not miss important subtleties in the wording of headlines and stories, because the content can be verified directly. So if you want to drill down into a topic, keep the Show Similar Content in the Feed option turned on. This is highly recommended before making an investment or business decision. Otherwise, if you just want to scan what is happening today, missing the subtleties in headline wording will not be problematic, and you can turn off the Show Similar Content in the Feed switch.
Built for Scalability and Performance
Similar Stories is a hugely compute-intensive undertaking. On high activity days, we may process millions of pieces of content in the CityFALCON pipeline, while even during slower times we regularly process up to a million per day. After aggregation and processing, all of that content must be compared against all the content we have already processed and stored from days past in order to determine similarity. The comparison process vectorises many dimensions of each piece of content then compares content dimension-by-dimension and cross-vector-wise. The resulting computation need is staggering.
This computation requirement made some popular languages like Java and Python too cumbersome to handle the huge data flows. For that reason, we wrote our Similar Stories Grouping component in C++, a strong language for performance and low overhead. The lower the overhead, the faster and more efficient the processing – and in this scenario, we needed any efficiency advantage we could obtain. Additionally, the flexibility to direct resource usage in C++ makes it ideal for tightly controlling computing and resource costs, particularly memory usage.
After quite a bit of R&D work, we produced a highly efficient version that delivers users what they need and keeps our processing costs manageable.
As the system scales, using low-overhead C++ ensures scalability is not compromised, so all CityFALCON clients, from high-powered API users to low-volume consumer users, experience smooth and accurate content delivery.
Reduce Your Research Time Today
We expect most users to benefit from this feature, so we turn it on by default. Test out the new feature on a really popular topics, like those on this watchlist highlighting popular stocks. Then enjoy more time to do business, be with friends and family, or pursue other uses of your time than wading through nearly identical content regarding your investments.
Leave a Reply